

A serendipitous combination of several factors including interesting talks (thanks CrikeyCon) and the release of fatal crash simulation data from Waymo has piqued my interest in machine learning.
Goes without saying but as a security lead/researcher I am looking at it as a source of vulnerabilities.
This post represents the first in a series of posts examining machine learning from a defensive security perspective. The overall series aims to collect the body of knowledge of defensive practices for ML models and attempt to implement them. To get the most out of it however, there has to be a bit of groundwork laid prior to looking at practical implementation. This post is going to look at a few security fundamentals modelled against the ML universe.
On with the show
Technology such as self driving cars represent the formation of a bridge between physicality and machine intelligence that until recently, didn’t exist. The growing acceptance of machine learning into fields such as diagnostic medicine and manufacturing further cements the foundations of this structure.

Diagnostic medicine is likely to change in ways we can’t imagine
This structure analogises the formation of a unique paradigm namely, the complete abdication of control to a machine. Lucky for me, because, paradigm shifts are generally where it gets interesting from a security perspective. In this instance abdication of control means that mistakes or exploits previously mostly resulting in financial penalties can have terrifying consequences. In terms of impact, exploitation of ML processes is where the rubber really hits the road:
- Misdirection of self-driving cars to mis-identify pedestrians or objects by using adversarial patterns or other means.
- Manipulation of ML medical diagnosis to delay interventional treatment by backdooring models taken from the internet or vendors.
- ML driven ransomware that drives factory floors to a standstill as a result of targeted malware spread via mis-interpreted input.
To clarify, most of these are edge cases and are for demonstrative purposes only. Some of these vectors are byproducts of automation not necessarily ML as well. Bottom-line upfront, I believe ML is going to change the way we live and if implemented securely and ethically it will be for the better.
That being said, a greater number of processes are exposing us to machine learning algorithms on a day to day basis. With every algorithm comes a set of user provided inputs and user provided inputs are entry points for abuse.
So how do we analyse the true threat landscape for Machine Learning?
Well security people have tools for this!
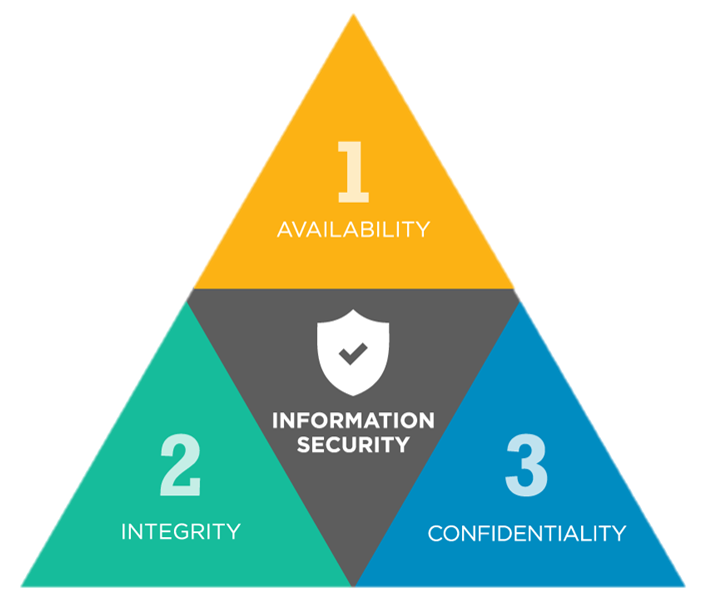
The f**king CIA triad
The CIA triad is a model used to develop security policies and identify problem areas. It breaks the approach down into three main domains:
Confidentiality:
- We want to protect confidentiality of information and data stored and processed by services
- Attackers want to breach that
Integrity:
- Information and services need to be consistent and known to not be tampered with
- Attackers want to tamper with information and manipulate it to their ends
Availability:
- Services and information are only useful if they are available for use
- Attackers want to hamper this
CIA is old and it has shortfalls but it is useful for a few key points
Confidentiality
- ML processes a lot of information and we need to make sure that information isn’t ripe for abuse
- Attackers will abuse ML services to leak information about entities
- Attackers will abuse ML services to infer information about entities
Integrity
- ML provides a lot of information and we need to ensure that information is correct
- Attackers will endeavour to corrupt the information within ML services to affect the utility and outcomes of the service
- Attackers will endeavour to corrupt information provided by ML services to enhance their own outcomes and aims
Availability
- If an ML service isn’t available when it is supposed to be things can go wrong
- Attackers will take ML services down or reduce their availability in an attempt to extort companies and individuals or do damage to individuals
So we have a baseline, but is there something perhaps more expansive and modern?
Well yes and no.
NIST has published a document entitled A Taxonomy and Terminology of Adversarial Machine Learning
- It covers the concept of adversarial machine learning pretty well
- Adversarial machine learning is a huge threat to ML
- But it’s not the only threat.
MITRE has the ATT&CK framework
- ATT&CK is a great framework that details Adversarial Tactics, Techniques & Common Knowledge.
- It only looks at known current techniques and tactics. Some of these are relevant to ML.
These frameworks are huge so unlike the CIA triad I am not going to break them down. They will however make appearances throughout this adventure.
We have our toolkit for examining potential attack vectors now, so where do we go from here?
The next post is going to examine machine learning and its different applications.
From there we will begin to model potential attacks using these frameworks. Once modelled and prepared we will begin to examine them in practice. We will then attempt to mitigate them using novel techniques. Finally, for all you GRC folks out there we will look forward using a risk based approach.
So bear with me on this one because its going to be a long ride. Also I am doing my OSCP at the moment and it’s conference season so this may not be entirely weekly, but I will do my best.

