

You can read Part 2 of this series here
Oh geez Rick, here we go again! Earlier than expected.

If you can’t tell, I am pretty excited about a new season of Rick and Morty.
Alright! So we know how Machine Learning works (really vaguely), so now let’s take a look at the possible attack vectors. When modelling threats it helps to diagram the processes we seek to examine. So let’s do that first. Also its looking like this one will be a two parter because its pretty damn big.
Peanut butter diagram time
To start with lets model a machine learning algorithm in a simple block diagram:
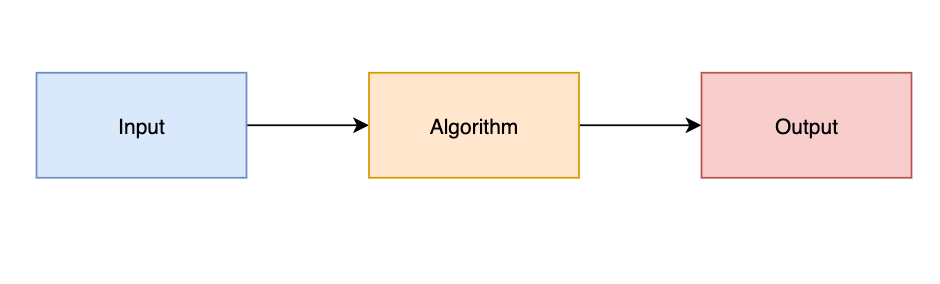
All programming in a nutshell
So we have an input namely data, the algorithm doing its algorithm things and its outputs being the things done to the data. Depending on the type of algorithm the data might be introduced in multiple phases e.g. training or integrated throughout the lifecycle of the algorithm. This model is super simplistic right but basically correct and as such is kind of useless for threat modelling. So let’s move forward from this.
A key differentiator in the lifecycle of an ML process is the process of training. So lets model that:
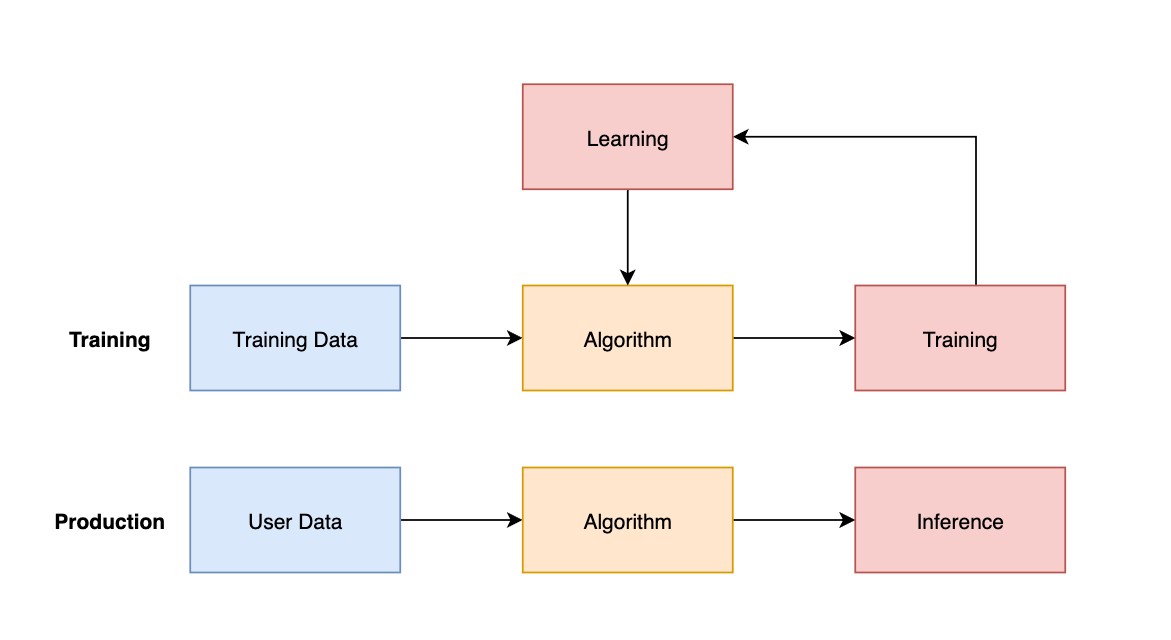
Training Plus stuff
Alright, so things are looking a little bit more complex here. We have a training process whereby the following things happen:
- Training Data is fed to the algorithm
- The algorithm derives learning
- The learning is integrated
- The process continues.
We’ve also transformed the previous implementation into the production swimlane where the following activities happen:
- Users (experts, you, your mother) provide data to the algorithm
- The algorithm does algorithmy things
- You get inference, a.k.a something derived out of the data. This might be songs you like, videos you want to watch or more hamsters running on wheels funding large companies.
Now, this doesn’t apply 100% to all types of machine learning discussed in part 2, because training isn’t necessarily part of the process for all algorithm types; but bear with me. We will be back.
But this model has some other issues:
- It doesn’t cover where the data comes from in production (or training for that matter)
- It doesn’t indicate where the algorithm is sourced from.
- It doesn’t indicate how the data is presented to the end user.
For the purpose of relevance we are going to modify the model a bit:
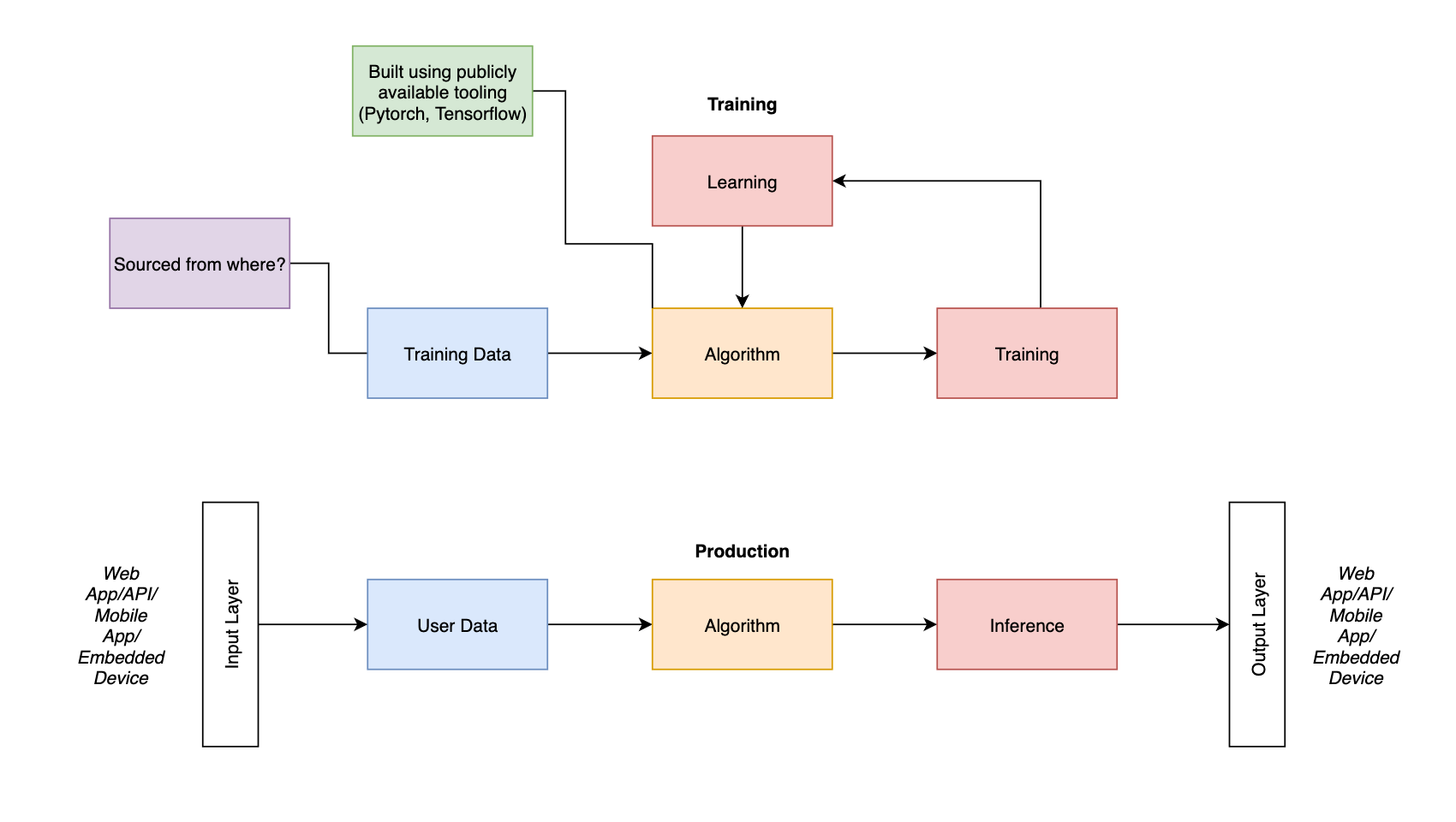
This grew quickly
Now we are cooking with AI.
So we’ve answered some of our questions above:
- The algorithm is likely based on publicly available open source tooling.
- Data is taken from an app of some kind, this app might run on a webserver, a mobile device or an embedded device.
- It’s also presented to the users via these formats as well.
One glaring thing stands out, namely, where is this magical training data coming from?
Well that all depends, training data takes many forms:
- Users (in unsupervised models)
- Data about users
- Imagery
- Medical Diagnostic data
- Video, depth and distance data
Where is the data is sourced from? Well, that might be some of the below places:
- Google Images
- Publicly available datasets
- Reputable places (medical clinics, research organisations)
Now before we continue to threat modelling it is worth pointing out: normal cybersecurity rules apply to ML. ML runs on servers (or “serverlesses”), it uses webservers, webapps, mobile apps and third party services. Protect your eggs people. I deal with this shit on a day to day basis.
Show me your threats
Ok, so we have an idea of what an ML process looks like, now let’s take a look at threats. It always helps me to model these things after a real life product, so let’s tell a bit of a story in the style of an AWS exam question.
There is a new company on the block, here to solve all of your worries: Don’t Die Incorporated. They have created an amazing machine learning product that identifies when you are imminently about to die and lets you know. Enjoy the moment of peace just prior to your inevitable death! They have employed you to help identify potential security risks with their new product.
But what the hell is a threat?
We have this classic image in security:
- There is an asset - a person on a rope. Yes a person, people do things. Not just men.
- They have a vulnerability - they have poor balance.
- There is a threat - Crocodiles
- There is an impact - Happy crocodiles or alternatively dead person.
Or in our case:
- The asset - Our beautiful shiny ML application that identifies your impending death
- The vulnerability - ????
- The threat - ????
- The impact - ????
A threat is any potential negative action or event against an asset that is enabled by the presence of a vulnerability.
We can break threats down by creating a sentence:
The person on the wire, fell into the crocodiles as a result of their poor balance and made the crocodiles respective days.
So let’s examining our machine learning model.
In the case of Don’t Die Inc’s deathvision 2.0 app they are using an image classification algorithm based on Keras. The algorithm itself is a semi-supervised learning algorithm meaning it requires training data to help identify potential causes of death, but can also learn from other input captured on a daily basis. The training data was sourced by crawling Google images for various images containing potential dangers to human life. The algorithm itself is exposed to the user via an API that is consumed by an app on their device. The app takes input from the environment in the form of images captured by the phones camera. Seems familiar right?
So lets break down potential issues here:
This post
- Training data comes from Google images
The next post
- Training can also come from user input
- Algorithm is open sourced
- Algorithm is exposed via an API
- API is accessed via a mobile application
- Image recognition is the game here
Training data issues
Alright, sourcing training data from Google images is a shitty idea. Image recognition operates best on consistent training data. Considering the way that these algorithms work, abnormalities in the coloration, size and consistency of images can cause unintended circumstances when it comes to fit. To put this in context: Imagine if every image had a lot of JPEG artifacting in it. The algorithm will likely pick up this and as such will likely match most artifact heavy images natively.

We’ve all seen this before: Artifacts courtesy of the Joint Photographic Experts Group
Given the importance of training data to the whole process it is essential that there are no issues. Artifacting is only one example. From a security centric standpoint obtaining data that can’t be verified is bad. If we think back to the good old CIA triad from Part 1 Confidentiality, Integrity, Availability. Training data from a source that is highly variable, easily corrupted and readily manipulated pretty much takes integrity out the back and shoots in the in the head.
Lets look at the ATT&CK Framework again (Part 1 yo.) because I can vaguely remember something….. ahhhh
Supply Chain Compromise
Adversaries may manipulate products or product delivery mechanisms prior to receipt by a final consumer for the purpose of data or system compromise.
This one is going to come up a few times by the way…
Images from Google images is a totally viable vector for supply chain compromise. A motivated attacker could manipulate the dataset (which is likely being collected by automatic processes to start with). In the least severe instance this will destroy the validity of the product. In the worst case it could get someone killed.
Read on in Part 2 in a day or so!

